Does It Mutate?

Explore methods that modify the original array alongside their descriptions and sample code. Distinguish between mutating and non-mutating methods through filtering.
About The Project
Discover JavaScript array methods and categorize them based on whether they alter the original array or not. Delve into each method to gain insights with comprehensive descriptions and illustrative code samples.
Project Goals
This project had a dual focus. Primarily, it aimed to acquire proficiency in web scraping using Playwright. Secondly, it sought to revamp the existing website, DoesItMutate. I frequently rely on this website to refresh my memory regarding array methods that induce mutations. However, one drawback I encountered was the cumbersome navigation to specific arrays. The sole search method available is the browser’s built-in search, which often yields multiple results, particularly inconvenient on mobile devices. In my redesign, I addressed this issue by incorporating a sticky sidebar for swift method selection on desktops and a user-friendly search bar with a dropdown menu of all methods for mobile users. Transferring all data manually from the original website would have been time-consuming, making this project an ideal opportunity to leverage a web scraper for automation.
Built With
-
Astro JS - Astro builds fast content sites, powerful web applications, dynamic server APIs, and everything in-between
-
Playwright - Cross-browser end-to-end testing for modern web apps
-
Shadcn UI - a collection of re-usable components for React
-
Tailwind CSS - a utility-first CSS framework that streamlines the process of building modern and responsive user interfaces
-
Figma - a cloud-based platform for creating interactive prototypes, designing components, and sharing design systems
Development
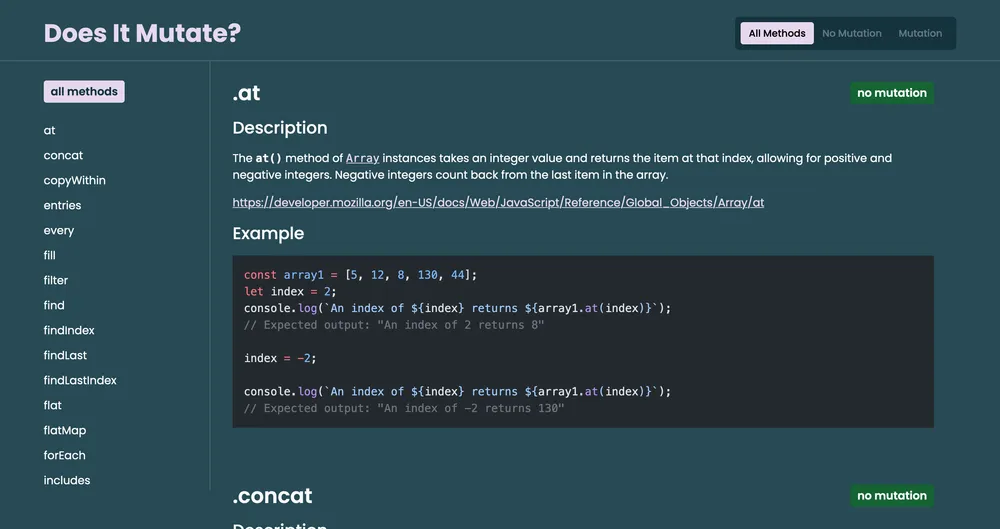
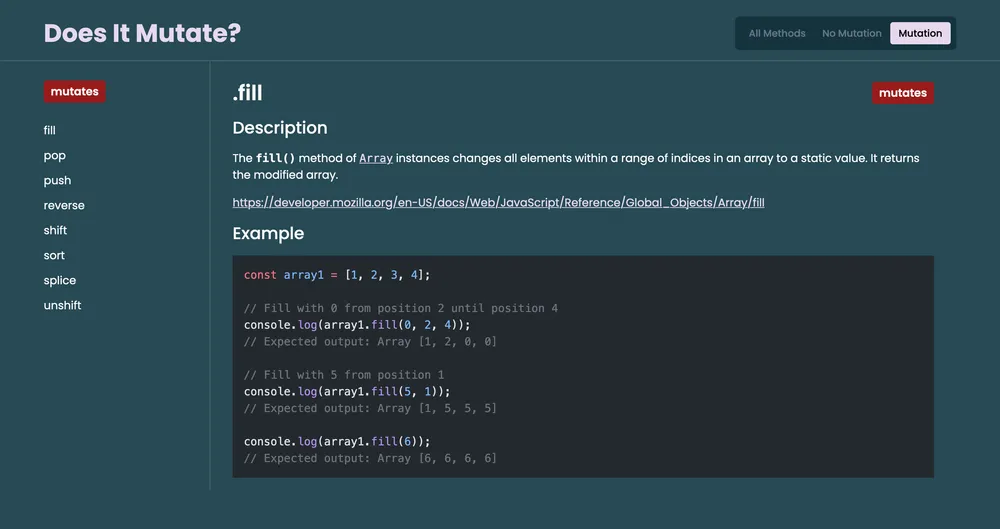
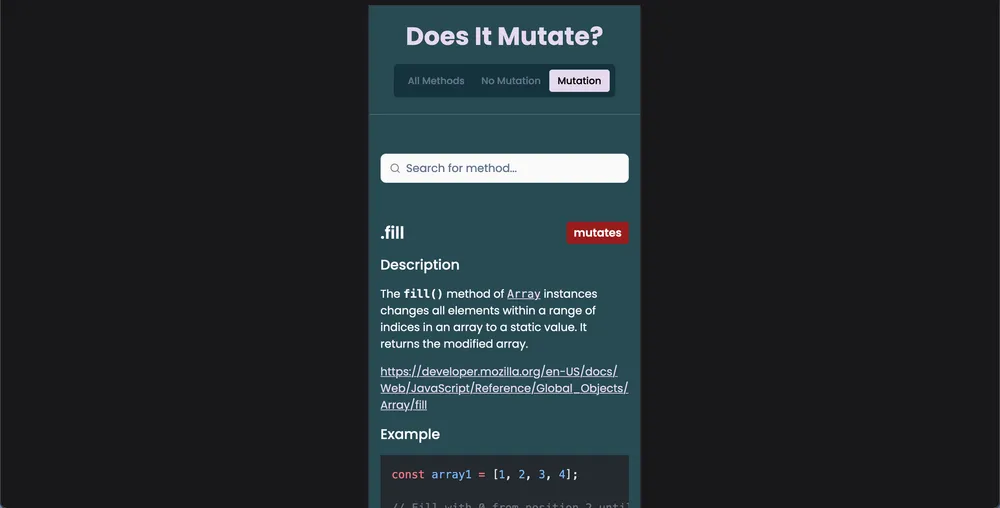
My initial step involved seeking out a color scheme that wasn’t the conventional black or white backgrounds. After exploring various palettes, I settled on one featuring a dark turquoise hue that resonated with me. Subsequently, I commenced crafting the prototype in Figma. As I delved into the design system, I initially incorporated both a search bar and a side bar list to facilitate easy navigation of the desired array methods. However, I soon recognized the redundancy of this approach and re-evaluated the design for both mobile and desktop platforms. For the mobile version, I opted for a search bar, while the desktop iteration featured a sidebar list. Each method would be represented by a card featuring a description, code example, link to MDN, and a badge clearly indicating its array mutation status. Additionally, I implemented a filtering mechanism based on mutation status, allowing users to toggle between “no mutation” and “mutation” methods via a button located in the top-right corner of the page.
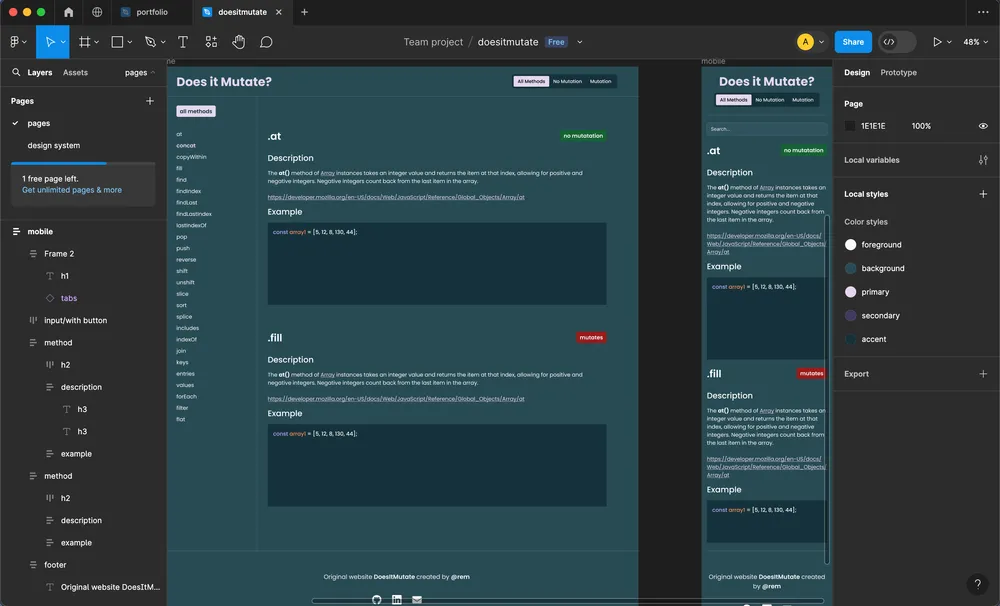
The primary objective of this project was to delve into web scraping techniques. Initially, I considered using Puppeteer, but after thorough research, I opted for Playwright. While Playwright is primarily designed for end-to-end testing, I discovered its smaller, dedicated package tailored for web scraping. Although it might seem like overkill for this specific project, I chose Playwright due to its versatility. Familiarizing myself with this library would prove beneficial for upcoming projects that require component and end-to-end testing.
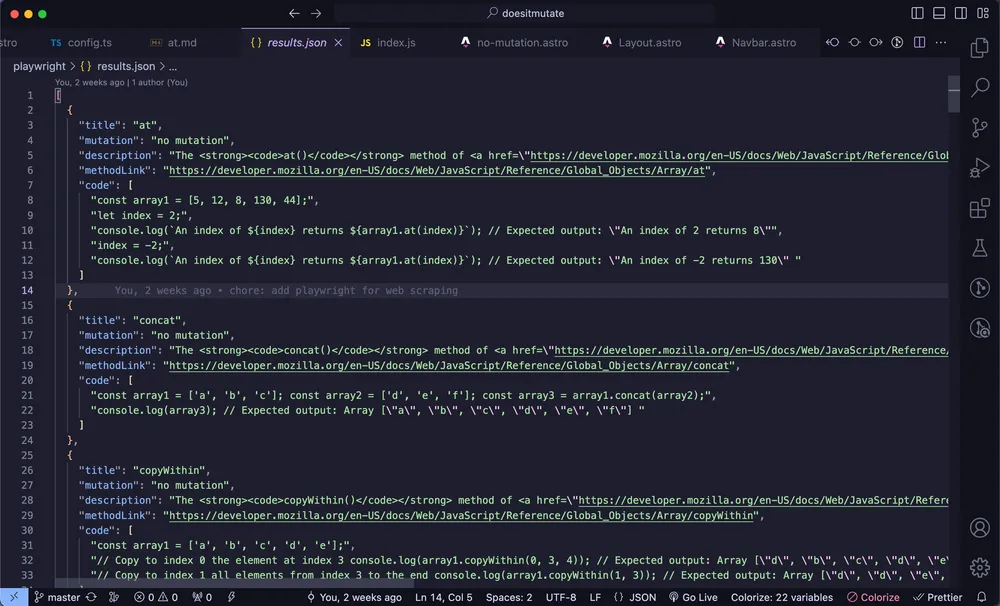
Understanding Playwright’s documentation was relatively simple. I crafted an asynchronous function within a JavaScript file which initiated a headless Chromium browser, directed it to the “Does It Mutate?” website, extracted the desired elements along with their inner text, stored the data in a JSON file, and closed the browser upon completion. While targeting and retrieving text from heading elements proved straightforward, extracting text from elements such as p and pre necessitated some trial and error before achieving the desired outcome.
const data = [];
for (const method of methodClass) {
const title = await method.locator("xpath=//h2/a").innerText();
const mutation = await method.locator("xpath=//p").first().innerText();
const description = await method
.locator("xpath=//p", { hasText: "The" })
.innerHTML();
const methodLink = await method.locator("xpath=//p").nth(2).innerText();
const codeBlock = await method.locator("xpath=//pre").innerText();
data.push({
title: title,
mutation: mutation,
description: description,
methodLink: methodLink,
code: codeBlock.split("\n").join(" ").split(" "),
});
}The data extracted was stored as an array of objects. Leveraging ChatGPT’s assistance, I successfully refined each object and organized them into a neatly formatted Markdown file with included frontmatter data tailored for utilization by Astro JS.
For frontend development, I opted for Astro JS due to its extensive support for content collections. These collections streamline document organization, frontmatter validation, and offer automatic TypeScript type-safety for all content. Each array method necessitated its own markdown file containing specific data. To ensure data integrity, I employed Zod to define a schema and export the collections object for registration.
import { z, defineCollection } from "astro:content";
const methodsCollection = defineCollection({
type: "content",
schema: z.object({
title: z.string(),
mutation: z.string(),
}),
});
export const collections = {
methods: methodsCollection,
};The content collection is accessed within an Astro file for rendering onto the page. There are three distinct pages, each featuring different queries to the content collection. One page retrieves all array methods, another fetches methods that do not induce array mutations, and the third gathers methods that do induce array mutations. Astro achieves this by examining the frontmatter data of all Markdown files, specifically the mutation string variable, which holds values of “mutates” or “no mutation”. Each page fetches the relevant data and presents it as a list on the left-hand side and as card components on the right-hand side for desktop users. On mobile, it exclusively displays the cards with a search bar positioned at the top. Tailwind’s typography plugin is utilized for styling the Markdown, with the prose class handling most of the formatting. The plugin also enables targeting specific elements, which proved advantageous as certain HTML elements were preserved during data scraping and customization from the website.
import { getCollection } from "astro:content";
// get all methods
const methods = await getCollection("methods");
// get methods that do not mutate an array
const noMutations = await getCollection("methods", ({ data }) => {
return data.mutation !== "mutates";
});
// get methods that mutate an array
const mutations = await getCollection("methods", ({ data }) => {
return data.mutation !== "no mutation";
});On each page, a tabs component is integrated into the navbar for seamless navigation. These tabs indicate the user’s current location through props. Fortunately, Astro provides convenient functionalities, including the ability to retrieve the current URL using Astro.url.pathname. This URL is then passed to the React tabs component via props along with the client:load directive to ensure immediate loading and hydration of the component JavaScript upon page initialization.
The search bar is exclusively visible on mobile devices, as it’s redundant on desktop screens. By employing Shadcn UI’s search component, I obtained a pre-designed search bar skeleton that could be seamlessly customized for my project. Upon focusing, the search bar unveils a dropdown menu containing all available methods. These methods are populated via the Astro query and transmitted as props. Additionally, the search bar is equipped with a client directive utilizing a media query. Implementing client:media="(max-width: 1024px)" ensures that the search bar is only rendered on screen sizes below 1024 pixels, targeting mobile devices and tablets while omitting larger desktop screens.
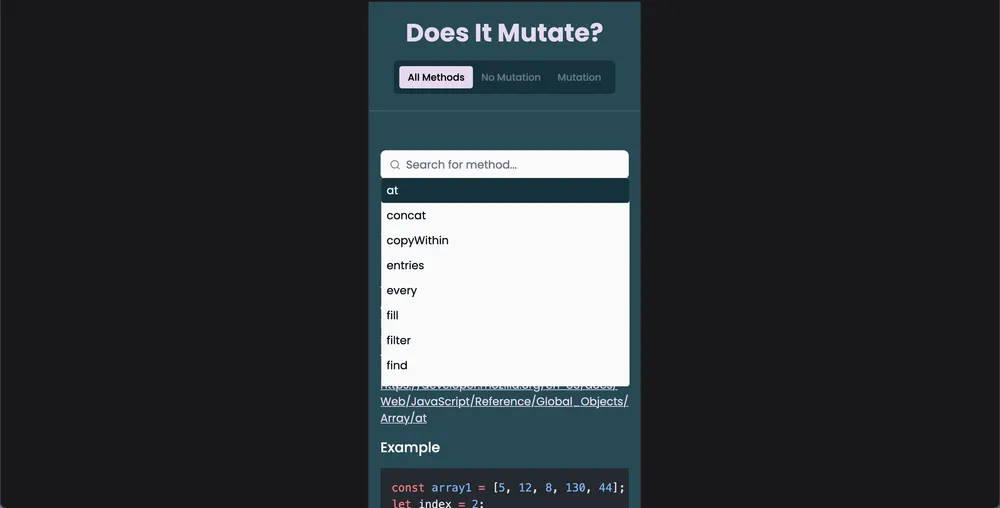
Challenges
Web scraping posed a challenge during this project. Despite the straightforward nature of Playwright’s documentation, I encountered difficulty due to nested HTML elements on the target website. Basic locators such as page.getByRole proved insufficient and I needed a more specific approach. After thorough research, I discovered an alternative method for targeting elements: XPath locators. An example that was used in this project looks like this: locator("xpath=//h2/a").innerText(), allowing me to precisely target the inner text within the a tag nested inside the h2 tag.
Extracting the code sections from the website posed another hurdle. These sections were riddled with numerous span classes, each with its distinct styling class. Fortunately, I managed to extract each line individually and organize them into an array. Subsequently, I utilized ChatGPT to refine and format the content for Markdown.
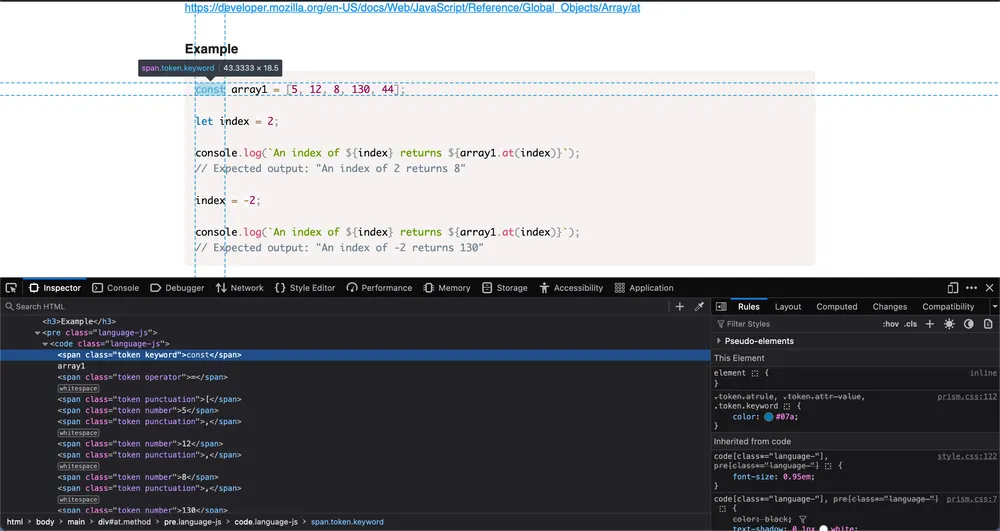
Learning Experience
This project provided valuable insights beyond just web scraping. In addition to automating data extraction, it introduced me to testing methodologies. By precisely targeting specific elements, it becomes possible to verify if a website meets specific requirements. Leveraging locator properties like hasText enhances specificity in testing. For instance, I utilized it to target the p tag and verify if it contained the text “The,” ensuring accurate targeting of the website’s method description section. The positive experience I had with Playwright has led me to consider it for future projects involving end-to-end testing.
Spotlight